The why of test parametrization
This article dives deeper into reasons and methods for parametrization in test automation. After you have completed it, you will have a deeper understanding of:
- What types of test parametrization techniques are available to you
- How proper test design works hand in hand with test parametrization
- How various approaches toward test design drive usage of different parametrization approaches
The target audience of this article is people already performing test automation activities, but who have yet to feel confident in their approach to the subject. Consider this article a friendly chat over coffee about the relationship between your automated tests and their parameters.
So first of all, let’s ask ourselves a couple of important questions:
How did we get here? How are tests designed?
Sure, there’s no one surefire and prescribed way to design your test cases. Do note that I said designing them, not simply writing them. The difference is tremendous. Unfortunately, in most teams that I had observed in my professional life, most test cases were written, as in pulled out of thin air. When you contrast it with designing test cases, the difference is clear as day and night:
| Written test case | Designed test case |
|---|---|
| often tests only happy path | if unhappy paths are ignored, it is an explicit decision |
| tends to have inconsistent requirements coverage | uses requirements to drive test case design, and rather the selection of test cases specified for execution is limited |
| may be based on loose assumptions instead of fixed requirements - or on actual implementation | requires stakeholders to specify the expectations beforehand |
It’s not to say, that written test cases are inherently bad, because they also tend to be more practical: their lifecycle is extremely pragmatic, and does not prescribe very rigorous processes to be upheld. But they also tend to be prepared based on implementation, not based on requirements.

But anyway - if you’ve ever heard of GTD, you also probably heard about so-called natural planning model. This is a term coined by David Allen to describe how our brain takes on a task of getting literally anything done.
On a similar note, ISTQB - International Software Testing Qualification Board - identifies a testing process with its actionable tasks and ongoing activities. For me, learning about it was the biggest enlightenment in the advanced level certification, and something that has helped me many times in my career. The testing process states, that a tester should plan their work, work from requirements, make tests as generic as possible/necessary, and report back with their findings. But there’s a twist that will be very important: how are the test cases prepared for the test plan.
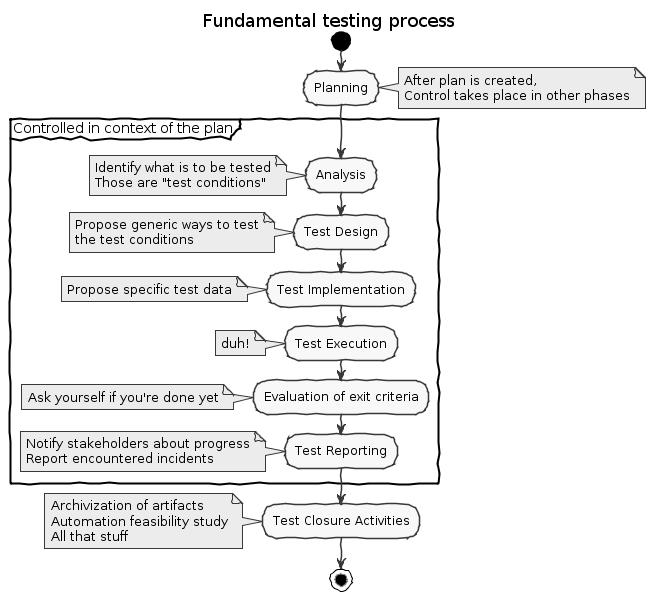
The part that interests us takes place between design and implementation steps. When designing the test case, the author identifies what is to be tested, and inputs data classes. Let’s take a practical example, and define tests for a website login functionality. The requirements are as follows:
- To log in, the user must provide username and password, and trigger a login button on the
/loginpage - Only valid combinations of login and password will allow user to complete the action
- After successful login, user will be redirected to page
/main
So the test flow for a positive case would look something like this:
- Open a browser to login page
- Enter valid username into username field
- Enter valid and matching password into password field
- Click “Login”
- Expect to be redirected to a webpage site
/main
This is a language-agnostic approach (and has a level of expressiveness that I’d expect from a test case - coincidentally this would also be a perfectly fine Robot Framework test case). You could probably execute this test case manually, if you pulled the proper data from your memory. In automation however, this is just not enough.
Question: if we were to automate this test case in your language of choice, would it always look the same? What if we wanted to verify that the login works for both Bob the Accountant and Jenny the Janitor? What are the actual test data? What if you wanted to run tests in two different test environments? What if the test deployment is literally deployed on another machine? What if during the development process the urls change? What if… You get the point. So let’s rework our example and put placeholders everywhere:
- Open a
${browser}to${host}${login-page-url} - Enter
${valid-username}into${username-field} - Enter matching
${valid-password}into${password-field} - Click
${login-button} - Expect to be redirected to a webpage site
${main-site-url}
We can generate a number of tests just by providing the test data:
| Variable | TC1 | TC2 |
|---|---|---|
| browser | firefox | chrome |
| host | http://localhost:8080 | http://test.acme.com |
| login-page-url | /login | /login |
| main-site-url | /main | /main |
| username-field | #username | #username |
| password-field | #password | #password |
| login-button | #login-btn | #login-btn |
| valid-username | bob@test.acme.com | jenny@test.acme.com |
| valid-password | hunter2 | huntress2 |
Now this is getting us somewhere.
Types of test data
“But Adam, most of these data don’t ever change!” I hear you yell from the back of the class. Well, you’re right, and you’re wrong. This example contains actually 3 different types of test data. It is true, that one of them usually does not change as often as the rest of them. Here’s a breakdown (remember: we’re still language agnostic here - this is true no matter which tool you use to automate tests):
| Variable | Variable type | Type description |
|---|---|---|
| browser, host | operational data | describe the context in which the tests will be executed: which environment, which [proxy], what browser, what locale, etc. |
| login-page-url, main-site-url, username-field, password-field, login-button | structural data | describe the structure of application, usually used to describe User Interfaces |
| valid-username, valid-password | actual test data | describe the data that actually differs on case-to-case basis. This is what you think differentiates specific test cases and groups SUT behaviours |
If you think about it, those types of test data also originate in different places:
| Variable type | Originates |
|---|---|
| operational | non-functional requirements, like compatibility matrix, or browser usage statistics; additionally: CI configuration |
| structural | application code conventions, configuration or code directly |
| actual test data | test case design process |
Practice
There are many ways to implement this in practice. The most straightforward, and least flexible one is of course to hard-code everything and ignore the fact that the highlighted terms are variables (ie. they may vary from test run to test run). This works, but you’ll soon hit maintenance bottleneck - you’ll be spending time on running search and replace over your automation code, instead of focusing on automating new tests.
Or you could do yourself a solid, and use proper code design to facilitate future requirements changes. It’s not premature optimisation, it’s engineering.
How would this look in terms of solutions used at a code level? Let’s take some automation solutions and compare:
| Variable type | xUnit | Mocha | Robot Framework |
|---|---|---|---|
| operational | project properties | Environment variables | Environment variables or Variable file |
| structural | Page Object Model | Page Object Model | Variable file |
| actual test data | Parameter provider object (ie. Using custom runner that supports parameterization | Custom parameterizer, or iteration | test data file |
Alternative ways of designing test cases
OK, not everyone uses a test design process in an explicit way, but there are other ways to create test cases. Like - specification by example. It is a great method, that allows you to clarify the requirements at their most critical lifecycle phase: early on. But what do you actually get out of specification by example? You get a set of test cases with some variables filled in. You still have to put in effort into translating it into a maintainable piece of code. Even if your examples contain hard-coded data, it pays off to analyse that data (and/or parameters of execution) and split them up into corresponding categories. Being aware of the categories of test data can only make this job easier.
 You buy me a Ko-fi
You buy me a Ko-fi